해당 포스트를 보기전 s3에 올라온 이미지를 aws lambda를 이용하여 썸네일 만들기를 먼저 보면 좋다.
기능
aws lambda에서 selenium과 requests등을 이용하여 국내 코인 거래소들의 공지사항을 크롤링 하여
텔레그램 오픈 채널의 봇으로 전송하는 기능
완료 된 비즈니스 플로우
git과bitbucket의pipeline을 이용하여git push후 바로deploy가 되도록CI구성- 1분마다
trigger함수가 작동하여crawler함수를 비동기로invoke하게 함. - 크롤링이 성공하면 최초
s3 bucket에 거래소별 현재 공지사항을 저장 - 2번째 크롤링 부터
s3 bucket에 저장되어 있는 공지와 현재 공지사항을 비교하여 새로운 혹은 수정된 공지 사항을 갱신하여 저장 - 텔레그램으로 갱신된 공지 사항 전송
trigger(lambda)
git push->CI(bitbucket pipeline)->1분 반복 trigger(lambda, cloud watch event rate 1)->invoke crawlercrawler(lambda)
git push->CI(bitbucket pipeline)->crawler(lambda, idle)->s3 butcket->telegram channle bot
requirements
OS
MacOx High Sierra 10.13.6
Docker 환경
Docker
Docker-compose
Docker-Desktop 맥과 윈도에선 이것들을 한번에
도커는 최대한
lambda환경과 비슷한 환경에서 작업 및 테스트를 해보기 위해 필요함.
local 환경
python==3.6
awscli==1.16.70
lambda 환경
python==3.6
boto3==1.6.18
botocore==1.9.18
selenium==3.141.0
beautifulsoup4==4.6.3
chromedriver-installer==0.0.6
python-telegram-bot==11.1.0
requests==2.20.1
Chrome 파일
chromedriver==2.37
headless-chromium=v1.0.0-37
시작
Step-1 IAM User 하나 만들기
루트 계정이 아닌 admin계정을 하나 만들어 사용.
IAM->사용자->사용자 추가->이름 ex) admin->프로그래밍 방식 액세스->기존 정책->AdminstratorAccess 추가->태그 생략->사용자 만들기->액세스 키 ID와비밀 액세스 키csv파일 저장 ->~/.aws/credentials파일을 열어 정보 저장aws cli configure를 이미 하였으면 아래에 추가 저장
[default]
aws_access_key_id = <AWS_KEY_ID>
aws_secret_access_key = <AWS_SECRET_KEY>
[admin]
aws_access_key_id = <발급 받은 액세스 키 ID>
aws_secret_access_key = <발급 받은 비밀 액세스 키>
이제
aws cli관련 기능을 사용할 때profile을admin으로 사용 함.
Step0 역할(Role) 만들기
- IAM -> 역할 -> 역할 만들기
- AWS 서비스(Lambda) -> 정책검색(AWSLambdaFullAccess, AmazonS3FullAccess) 후 체크박스 체크
-> 태그 추가(패스) -> 검토 역할 이름 ex)scraper -> 역할 만들기
trigger와crawler둘다 같은role을 쓸 것이다.
Step1 크롤링 코드 추가
├──src
│ ├── __init__.py
│ ├── crawler.py
│ ├── exchange
│ │ ├── __init__.py
│ │ ├── base.py
│ │ ├── bithumb.py
│ │ └── coinone.py
│ └── utils
│ ├── __init__.py
│ ├── other.py
│ ├── s3_controller.py
│ └── webdriver_wrapper.py
s3_controller.py에 있는AWS_BUCKET_NAME은 나중에lambda의 환경 변수에 넣을 것base.py에 텔레그램 정보 또한lambda의 환경 변수로 따로 넣어 주도록 함.lambda에서boto3를 사용 할때credentials를 넣어 주지 않는 이유는lambda에서 호출되는 다른 서비스는 해당 람다의role의 권한을 가지고도 실행이 가능하기 때문이다.Docker에서는 AWS_관련 키를 넣어주어야 한다. 어떻게?docker-compose의aws_env를 이용해서!- 최상위 폴더에
.aws.env을 만들고 자격증명 키를 넣는다
중요!!!!!
세번 읽으시오!
여기서 중요한것 .gitignore에 .aws.env 파일을 추가하여 깃에 올리지 말것!!!!!!!
Step2 Makefile, Dockerfile, docker-compose.yml 만들기
lambda에 올리기전 해당 프로젝트를 docker를 이용하여 테스트를 해보자.
Makefiledocker-build: # Dockerfile Build docker-compose build docker-run: # docker-compose.yml의 lambda 서비스 run docker-compose run lambda clean: # 패키징 관련 파일 clean rm -rf crawler crawler.zip rm -rf __pycache__ fetch-dependencies: # 패키징 관련 종속 파일/디렉터리 추가 mkdir -p bin/ mkdir -p lib/ # Get chromedriver chromedriver파일이 없으면 다운로드하여 bin에 압축해제 if [ ! -e "bin/chromedriver" ]; then \ curl -SL https://chromedriver.storage.googleapis.com/2.37/chromedriver_linux64.zip > chromedriver.zip; \ unzip chromedriver.zip -d bin/; \ rm chromedriver.zip; \ fi # Get Headless-chrome 동일 if [ ! -e "bin/headless-chromium" ]; then \ curl -SL https://github.com/adieuadieu/serverless-chrome/releases/download/v1.0.0-37/stable-headless-chromium-amazonlinux-2017-03.zip > headless-chromium.zip; \ unzip headless-chromium.zip -d bin/; \ rm headless-chromium.zip; \ fi build-crawler-package: clean fetch-dependencies # 크롤러 패키징 clean -> fetch-dependencies -> 진행 # crawler 폴더안에 src, bin, lib폴더를 복사 # lib폴더에 requirements.txt 로 관련 모듈 설치 # crawler.zip으로 압축 mkdir crawler cp -r src crawler/. cp -r bin crawler/. cp -r lib crawler/. pip install -r requirements.txt -t crawler/lib/. cd crawler; zip -9qr crawler.zip . cp crawler/crawler.zip . rm -rf crawler make-crawler-s3-upload: build-crawler-package # 패키징 파일 s3 업로드 # crawler.zip을 만들고 바로 s3 업로드 aws s3 cp crawler.zip s3://${BUCKET_NAME} --profile=${PROFILE}DockerfileFROM lambci/lambda:python3.6 MAINTAINER tech@21buttons.com USER root ENV APP_DIR /var/task WORKDIR $APP_DIR # bin폴더와 lib폴더를 도커에 복사 COPY requirements.txt . COPY bin ./bin COPY lib ./lib # requirements 도커에 설치 RUN mkdir -p $APP_DIR/lib RUN pip3 install --upgrade pip RUN pip3 install -r requirements.txt -t /var/task/lib # /var/task가 프로젝트의 라이브러리가 있는 곳docker-compose.ymlversion: '3' services: lambda: build: . env_file: # aws credentials를 docker에서 쓰기 위한 것 - ./.aws.env environment: # lambda에서 소스와 라이브러리를 찾기 위한 환경변수 설정 - PYTHONPATH=/var/task/src:/var/task/lib - PATH=/var/task/bin volumes: - ./src/:/var/task/src/ command: src.crawler.crawler_func
Step3 도커빌드 해보기
-
s3에 기본옵션의bucket을 하나 생성 .aws.env파일을 루트 디렉토리에 생성AWS_REGION=<AWS_REGION> AWS_BUCKET_NAME=<AWS_BUCKET_NAME> AWS_LAMBDA_ROLE=<AWS_LAMBDA_ROLE> AWS_ACCESS_KEY_ID=<AWS_ACCESS_KEY_ID> AWS_SECRET_ACCESS_KEY=<AWS_SECRET_ACCESS_KEY> AWS_PROFILE=<AWS_PROFILE> AWS_LAMBDA_FUNC_NAME=<AWS_LAMBDA_FUNC_NAME> TG_BOT_API_KEY=<TG_BOT_API_KEY> TG_CHANNEL_LINK=<TG_CHANNEL_LINK>-
빌드전 종속성 추가
make fetch-dependencies를 하면lib폴더와bin폴더가 생성되고bin폴더 안에는 크롬 드라이버 관련 파일이 다운받아져 있는것을 확인할 수 있다. -
빌드
make docker-buildordocker-compose build후 빌드가 성공 하면 - 실행
make docker-runordocker-compose run lambdaordocker-compose up
실행이 제대로 되었다면 지정 해놓은bucket에data/bithumb.txt파일이 생겼을 것이다. 이 파일로 새로운 공지 사항을 파악하는 것.
.aws.env파일은 절대절대 git에 포함되어서는 안된다
Step4 람다 함수 만들기
create_lambda.sh파일을 만든다#!/bin/bash while read LINE; do eval $LINE done < .aws.env REGION=${AWS_REGION} FUNCTION_NAME=${AWS_LAMBDA_FUNC_NAME} BUCKET_NAME=${AWS_BUCKET_NAME} S3Key=crawler.zip CODE=S3Bucket=${BUCKET_NAME},S3Key=${S3Key} ROLE=${AWS_LAMBDA_ROLE} HANDLER=crawler.crawler_func RUNTIME=python3.6 TIMEOUT=60 MEMORY_SIZE=512 ENV="Variables={PATH=/var/task/bin,PYTHONPATH=/var/task/src:/var/task/lib,AWS_BUCKET_NAME=${AWS_BUCKET_NAME},TG_BOT_API_KEY=${TG_BOT_API_KEY},TG_CHANNEL_LINK=${TG_CHANNEL_LINK}}" PROFILE=${AWS_PROFILE} # 파일을 패키징하여 s3에 업로드 후 make make-crawler-s3-upload BUCKET_NAME=${BUCKET_NAME} PROFILE=${PROFILE} # 람다를 만든다! aws lambda create-function \ --region ${REGION} \ --function-name ${FUNCTION_NAME} \ --code ${CODE} \ --role ${ROLE} \ --handler ${HANDLER} \ --runtime ${RUNTIME} \ --timeout ${TIMEOUT} \ --memory-size ${MEMORY_SIZE} \ --environment ${ENV} \ --profile ${PROFILE}-
실행 빠밤
./create_lambda.sh만약permission denied가 날경우chmod 755 create_lambda.sh후 재 실행 - 확인
aws웹 페이지를 가서 파일을 업로드 한bucket을 확인해보자.
crawler.zip이 있으면 성공.
lambda로 가서 새로운 람다 함수가 생겨 있으면 성공!
해당 함수로 접속하여 환경 변수를 보면create_lambda.sh에 넣은ENV가 잘 들어가 있는것을 확인할 수 있다.
다른 부분(Role,func_name)들도 잘 들어 가있으면 성공!
step5 람다 함수 업데이트 하기
소스를 수정했을 경우 해당 소스를 다시 패키징 하여 람다 함수를 업데이트 해줘야 하는데
이를 간단한 스크립트로 만들어서 해보자. 방식은 create_lambda.sh와 매우 유사 하다!
update_code_lambda.sh만들기#!/bin/bash while read LINE; do eval $LINE done < .aws.env FUNCTION_NAME=${AWS_LAMBDA_FUNC_NAME} ZIP_FILE=fileb://crawler.zip BUCKET_NAME=${AWS_BUCKET_NAME} KEY=crawler.zip PROFILE=${AWS_PROFILE} # 파일을 패키징하여 s3에 업로드 후 make make-crawler-s3-upload BUCKET_NAME=${BUCKET_NAME} PROFILE=${PROFILE} aws lambda update-function-code \ --function-name ${FUNCTION_NAME} \ --s3-bucket ${BUCKET_NAME} \ --s3-key ${KEY} \ --profile ${PROFILE}- 실행
./update_code_lambda.sh를 실행하면 파일을 새로 패키징하고s3에 업로드 한후 람다함수를 업데이트 한다. 결과는 람다 함수의 정보가 나오면 성공.
텔레그램 봇 만들기는 mac버전으로 작성 되었습니다.
step6 텔레그램 봇 만들기
텔레그램을 다운 받은후 BotFather을 찾아가서(검색해서) 말을 걸어 봅니다.
-
헤이
/start
-
/newbot
-
봇의 이름을 적어줌.

-
봇의 유저네임을 적어줌
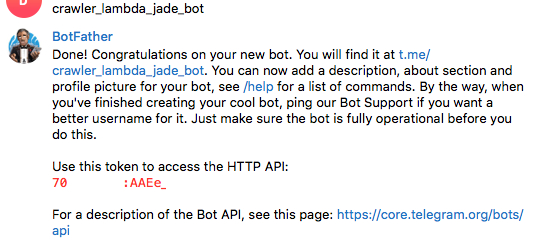
이러면 마지막 사진에 XXXX:YYYY의 형태로 API_KEY가 보인다. 봇이 만들어 진 것이다.
step7 텔레그램 채널 만들고 봇 넣기
이번엔 채널을 만들어 보자. 그리고 봇을 채널에 넣어보자.
-
New Channel를 누른후 채널명을 적고 다음화면에서 타입을Public으로 하고 아래 빈칸에 해당 채널의 링크를 만들어 넣자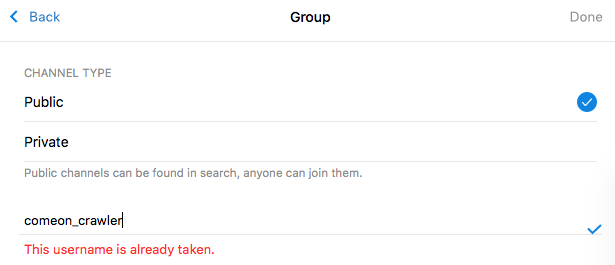
-
그리고 채널을 만들고 채널 정보를 찾아가서 보면 해당 링크로 만들어 진것을 볼 수 있다.
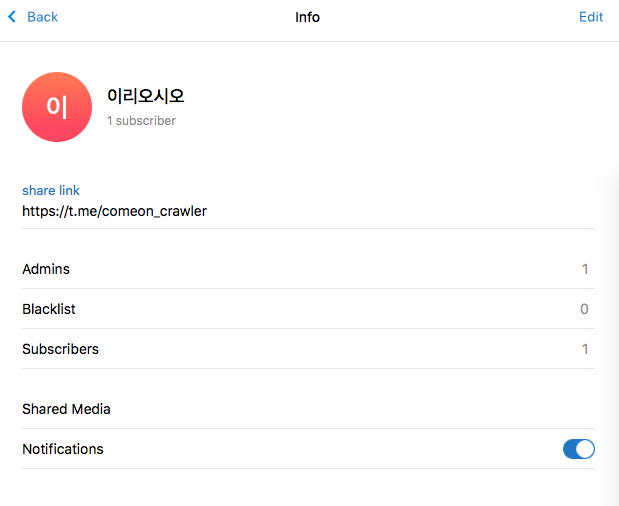
-
봇을 초대 해보자.
info에Add Admin을 찾아가서 검색후 초대! 초대가 성공 하면 이렇게!
초대가 성공 하면 이렇게!
step8 텔레그램 정보를 .aws.env에 갱신하고 람다 함수 업데이트 하기
.aws.env업데이트... TG_BOT_API_KEY=<70XXXXX:AAEe_YYYYYYYYYYYYYY> TG_CHANNEL_LINK=<@link>- 텔레그램 테스트용 코드 작성
tg_test.pyimport telegram def main(): with open('.aws.env', 'r') as f: lines = f.readlines() env = dict(s.rstrip().split('=') for s in lines) token = env.get('TG_BOT_API_KEY') chat_id = env.get('TG_CHANNEL_LINK') bot = telegram.Bot(token=token) chat_id = chat_id bot.sendMessage(chat_id=chat_id, text='<b>안녕하세요?</b>', parse_mode=telegram.ParseMode.HTML, disable_web_page_preview=True ) if __name__ == '__main__': main() - 실행 및 결과 확인
python tg_test.py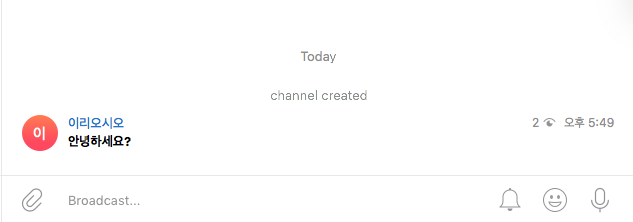
비트버켓을 사용하시는 분만 보시면 되는 부분 입니다.
step9 bitbucket pipeline을 통해 git push후 바로 람다 함수가 업데이트 되게 하기
aws cli사용 하는 부분중PROFILE부분을 제거make make-crawler-s3-upload BUCKET_NAME=${BUCKET_NAME} PROFILE=${PROFILE} -> make make-crawler-s3-upload BUCKET_NAME=${BUCKET_NAME}모두 제거해야함. (아마도..)
bitbucket-pipelines.yml작성image: python:3.6 pipelines: default: - step: script: - apt-get update - apt-get install -y zip - pip install --upgrade pip - pip install awscli --upgrade - ./update_code_lambda.sh딱히.. 뭐없다 테스트 코드를 짜지 않았기 때문에 단순히 업데이트만 가능하게 작성함.
awscli를 설치후./update_code_lambda.sh를 실행만 했다bitbucket의pipeline에 사용할setting값 설정
1).repository->settings->PIPELINES->Settings->Enable Pipelines켬
2).repository->settings->PIPELINES->Repository variables에Name,Value를 넣으면$NAME형태로 사용 가능하다.AWS_ACCESS_KEY_ID AWS_DEFAULT_REGION AWS_SECRET_ACCESS_KEY AWS_LAMBDA_FUNC_NAME AWS_BUCKET_NAME넣어 준다.
value도 같이- 그리고
git push를 하면 비트버켓에서 해당yml스크립트를 실행한다.
Pipelines에 가보면 해당 스크립트가 통과되었는지 나타난다.
끝!
이 아니라 다음편에 이 크롤러를 작동 시키는 trigger를 lambda로 만들어야 비로소 완성 된다.
Comments