UiPath Studio의 Tesseract OCR을 사용 할 때 한국어를 인식 하고 싶은 경우가 있다.
어떻게 하면 한글을 읽을 수 있는지 알아 보자.
일단 아래와 같이 기본적인 Get OCR Text 액티비티로 메모장의 글자를 읽어 보자.
-
Get Ocr Text Sequence
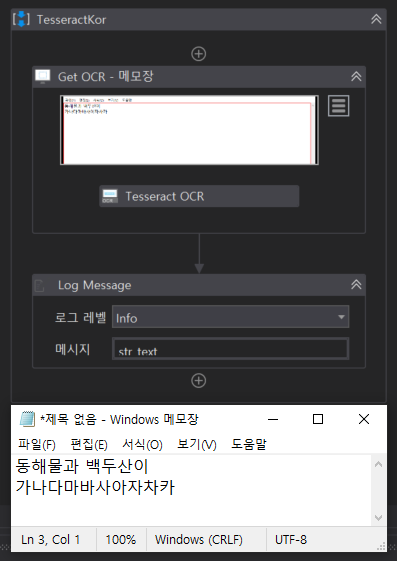
-
Get Ocr Text 액티비티의 속성
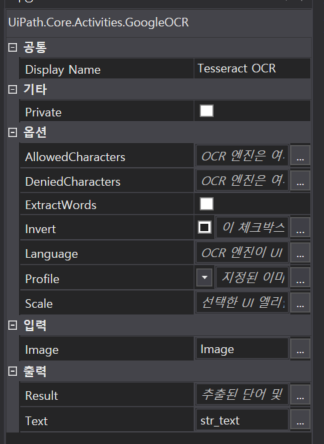
-
결과
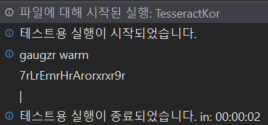
한글을 인식하지 못하고 잘못된 결과를 반환한다.
한글을 인식하고 싶으면 Tesseract의 kor.traineddata가 필요 하다. 이 파일은 아래 링크에 접속하여 받을 수 있다.

한글을 트레이닝한 파일을 받아 UiPath Studio가 설치 된 위치에 tessdata라는 폴더를 만들고 넣어야 한다.
- 파일위치
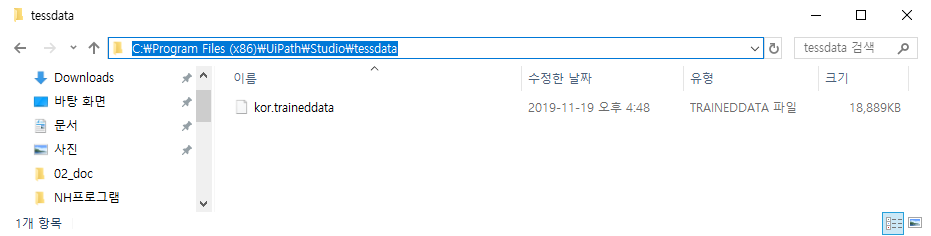
그리고 Get OCR Text 액티비티의 속성을 수정하고 실행 해보자
-
속성수정
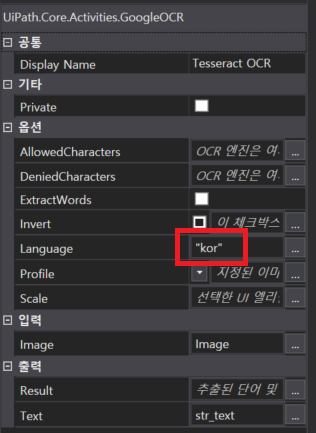
-
실행 결과

한글이 인식되어 나오는것을 확인 할 수 있다.
Comments